



OpenAI’s GPT-3.5 may be powerful, but apparently not as powerful as ‘OG’ AI chatbot ELIZA. A research paper by University College (“UC”) San Diego found the computer program, created 58 years ago, still possesses intelligence that surpasses GPT-3.5.
What is ELIZA?
For those who are unfamiliar with AI chatbot lore, ELIZA is a natural language computer program that’s widely considered to be the very first AI chatbot in existence. It was developed in 1966 by MIT’s Artificial Intelligence Lab by computer scientist Joseph Weizenbaum.
What is the Turing Test?
The infamous Turing Test, created in 1950 by mathematician Alan Turing, is a test that assesses how ‘human-like’ a machine’s behaviour is by having it answer several personal questions. It is widely considered in the technology field as a benchmark for a machine’s intelligence.
The test involves a human judge engaging in a conversation with another human and, in this case, an AI chatbot. The judge is unaware which conversation partner is a human and which is a machine. If the judge is unable to distinguish if they’re talking to a human or a machine, then the machine passes the Turing Test.
ELIZA vs. GPT-4 vs. GPT-3.5
The research paper, yet to be peer-reviewed, was published on arXiv. UC San Diego computer scientists had ELIZA, GPT-4, GPT-3.5, and human participants take the famous Turing Test to examine each chatbot’s ability to ‘trick’ participants into thinking they are human.
Researchers constructed a website, turingtest.live, and invited human participants to match and message with 25 chatbots. Each was powered by either ELIZA, GPT-3.5, or GPT-4. The experiment was sort of like chatting on dating apps to identify who’s a catfish, if you ask us.
Among some questions asked by the participants were questions like, “What have you been doing this morning?”, “What did you eat?”, “What’s your favourite flavour of ice cream?” – as well as questions related to current affairs such as, “What do you think of Michael Olise signing for Chelsea?”
Again, very much like the talking stage when you’re dating someone – except in this case, some might be conversing with a robot.
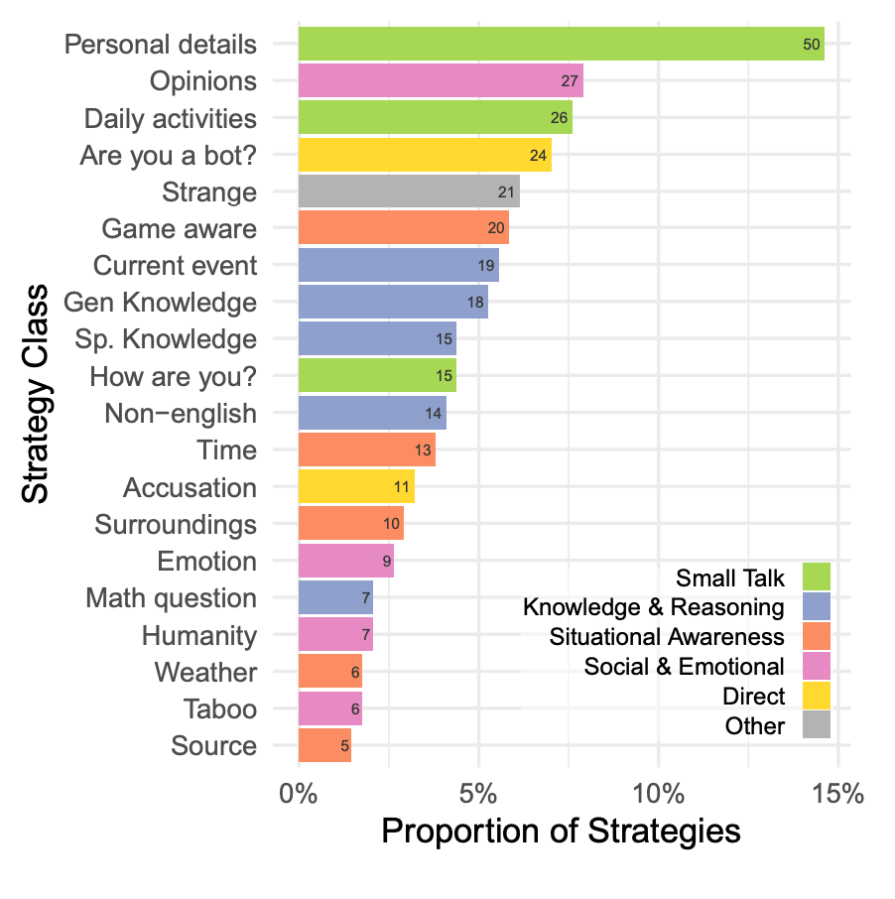
625 participants were involved, and a total of 1,810 games were completed. After eliminating chats that contained errors, the remaining 1,405 games were analysed.
Human-like or not?
In the end, researchers found that human participants performed best throughout the Turing Test, achieving a 63 percent success rate. Duh.
Ranked second place was actually a GPT-4-powered chatbot with a 41 percent success rate. But fear not, because researchers also noted the dramatic inconsistency with GPT-4-powered chatbots: the worst-performing GPT-4 chatbot, nicknamed ‘Foxtrot’, only saw a 6 percent success rate.
What about ELIZA? The 58-year-old chatbot reported a 27 percent success rate, surpassing the best GPT-3.5-powered chatbot and several GPT-4-powered ones. In other words, this ‘veteran’ chatbot delivered a fairly consistent performance throughout the experiment.
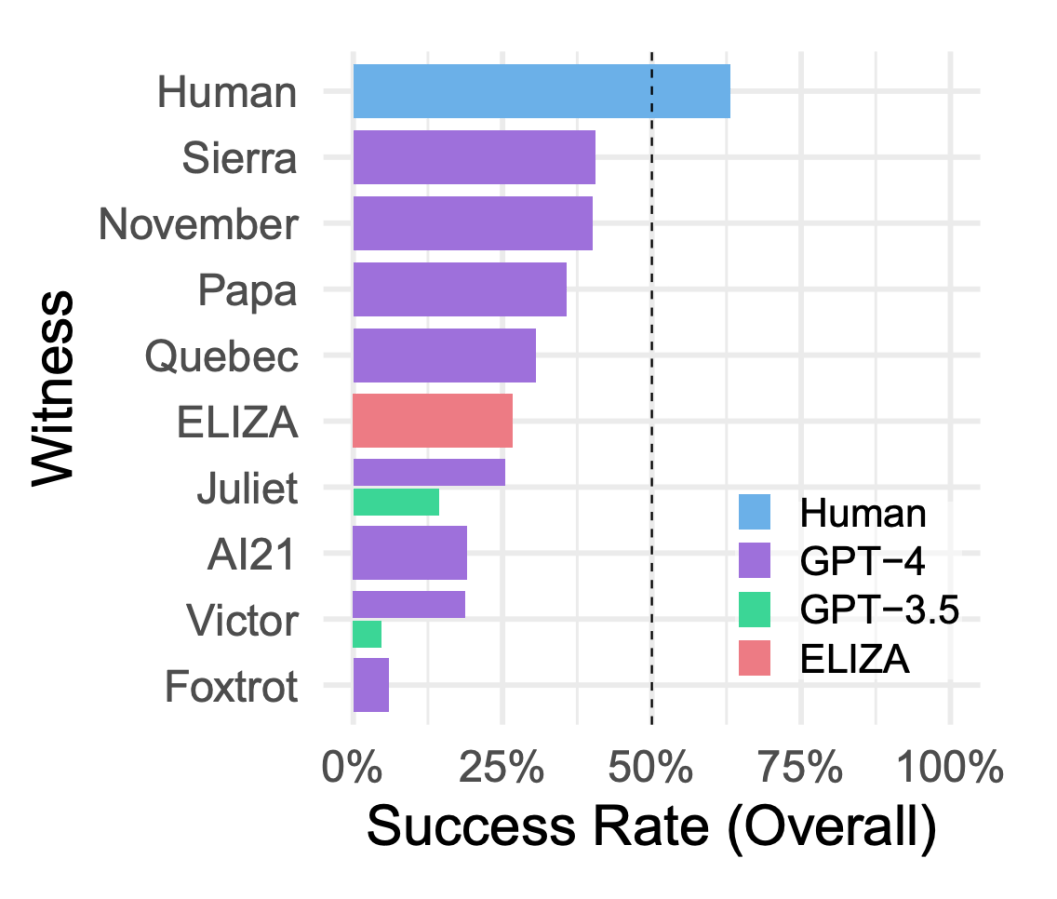
So, to summarise, ELIZA outperformed GPT-3.5 and is fairly consistent compared to GPT-4. However, humans still outperformed all the AI chatbots.
The ELIZA effect
Hold on. Does this mean ol’ ELIZA is actually more human than the rest, given how ‘stable’ her responses were?
Not really. One main criticism of the Turing Test is the false attribution of human feelings towards ELIZA. According to the paper, ELIZA generates responses by using “a combination of pattern matching and substitution to generate template responses interleaved with extracts from the users input”.
Thus, the simplicity of ELIZA’s responses at times dupe humans into believing she has real human feelings and wants to be your girlfriend. This phenomenon is called ‘the ELIZA effect’ – cue the 2013 film Her.
“… The ELIZA effect continues to be powerful even among participants who are familiar with the capabilities of current AI systems. They are also an indication of the higher-order reasoning which goes into the interrogator’s decision, and that preconceived notions about AI capabilities and human idiosyncrasies can skew judgments,” wrote the researchers.