




What happens when large language models (LLMs) hoover up so much data online that, one day, they run out of data to scrape from?
Enter “copyright laundering” or “data laundering”. It’s a murky practice in which AI software — art generators, for instance — steal data and obscure the source of said stolen data. The data can then be sold to other companies for commercial use.
A most recent example is what’s occurring on HuggingFace, a platform hosting datasets that can be shared among thousands of AI developers. AI copyright expert Ed Newton-Rex claims that HuggingFace “facilitate[s] copyright laundering” via its latest product, Cosmopedia.
How so?
AI: Where’s the data from?
Generative AI models need to be “fed” and trained on data. Most of the time, the data is taken from the internet – online pages, blogs, news articles, and so on.
Cosmopedia is a massive treasure trove that contains such datasets, offering users 30 million text files and 25 billion “tokens” — in AI terms, they’re pieces of words fed into a system — that can be used to train generative AI models.
However, Cosmopedia’s dataset is not its own. It was trained from another dataset called Mixtral, which was developed by French-based Mistral AI. Nobody knows where Mixtral’s dataset came from.
In other words, Cosmopedia is taking another company’s dataset and passing it off as its own, for others to use.
“You don’t want to train directly on copyrighted work for fear of being sued, so you train on text that was created by a model that itself was trained on copyrighted work. You launder the copyright,” explained Newton-Rex on X.
“HuggingFace has a positive reputation of being a community for developers to come together and share open source codes … [but] they do have a commercial imperative, as they’ve raised millions of dollars [from investors],” Professor Toby Walsh, Scientia Professor of Artificial Intelligence at the University of New South Wales, told The Chainsaw.
“Synthetic data”: Copyrightable?
HuggingFace and Cosmopedia describe what they provide as “synthetic data”. In simple terms, it’s data that’s artificially generated rather than data created based on real-world samples. Individuals and companies that use said data are, presumably, shielded from copyright laws as a result.
“If you look at what the content is, it might well be copyrighted material, which is why it’s useful data in the first place. If it was really synthetic data, [it] wouldn’t bear any resemblance to real things,” said Walsh.
Copyright laundering in AI art generators
In early March, popular AI art generator Midjourney accused Stability AI employees of stealing its code for prompts and images. Midjourney swiftly banned all Stability AI employees from using its services as a result.
Some in the tech community saw irony in the spat between two parties, as Midjourney and Stability AI both have a reputation for training its datasets on artists’ works.
In Midjourney’s case, the company’s developers discussed laundering the scraped artwork — allegedly from 16,000 artists — “through a fine tuned Codex”. The “Codex” presumably referred to a tool by OpenAI that processes natural language and generates code in response.
“At some point it really becomes impossible to trace what’s a derivative work in the eyes of copyright,” wrote a member on Midjourney’s Discord chat.
“All you have to do is just use those scraped datasets and conveniently forget what you used to train the model. Boom legal problems solved forever,” wrote another member.
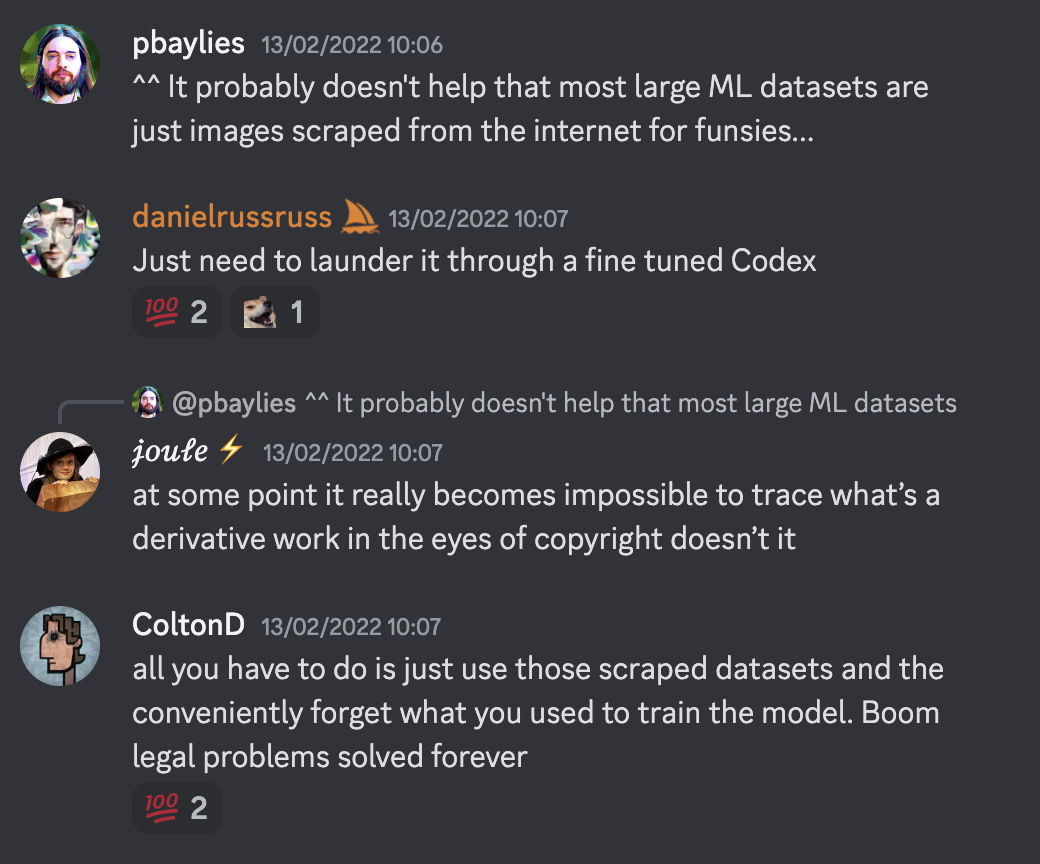
“Though [the] defendants like to describe their AI image products in lofty terms, the reality is grubbier and nastier: AI image products are primarily valued as copyright-laundering devices, promising customers the benefits of art without the costs of artists,” read the artists’ complaints in a lawsuit against Midjourney and Stability AI filed in 2023.
Is this lawful?
Unfortunately, copyright laundering is a relatively new practice in the AI space. “People are only starting to wake up to the idea of [the practice] being a subterfuge,” said Walsh. “The [practice of] disguise when generating data is the ‘poison fruit’ in the AI industry.”