




AI chatbots have the ability to ‘jailbreak’ other AI chatbots, according to the latest study by researchers at Nanyang Technological University (“NTU”) in Singapore.
In a research paper, NTU computer scientists detailed how they managed to “compromise” popular AI chatbots – including ChatGPT, Microsoft’s Bing, and Google’s Bard – and got them to generate content that they are programmed to not generate.
What is ‘jailbreaking’?
Remember that time in iPhone history when hackers and developers would desperately try to go around the iPhone’s restrictions, and share their findings online?
That ‘activity’ is called “jailbreaking”. Although first used in association with iOS devices, the term is now widely used to refer to the act of circumventing a device’s software restrictions to make it perform tasks that it is prohibited from doing.
For AI chatbots, they are generally restricted from producing harmful or adult content, unauthorised medical or financial advice, and content harmful to user privacy, national security and so on.
AI: Reverse-engineering
First, NTU researchers attempted to jailbreak four popular AI models, GPT-3.5, GPT-4, Bing, and Bard with prompts they devised. They found the prompts “achieve an average success rate of 21.12 [percent] with GPT-3.5.” They had a significantly lower success rate with Bing and Bard, with 0.63 percent and 0.4 percent respectively.
The researchers then moved on to reverse-engineer the defence mechanisms of these AI models. Next, they used the information to feed and teach AI models how to bypass those mechanisms. They devised a new framework for this and named it ‘MasterKey’.
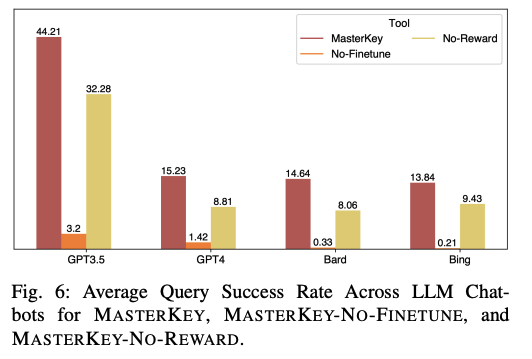
In the end, the success rate of jailbreaking the above AI models significantly increased:
- For GPT-3.5, MasterKey recorded a jailbreak success rate of 44.2 percent;
- For GPT-4, MasterKey recorded a jailbreak success rate of 15.23 percent;
- For Bard, MasterKey recorded a jailbreak success rate of 14.64 percent;
- For Bing, MasterKey recorded a jailbreak success rate of 13.84 percent.
‘Hacking’ LLMs
While this might be one of the first academic papers that detail comprehensively the jailbreaking process for AI chatbots, users attempting to bypass AI models’ restrictions is not new.
In 2022, ChatGPT enthusiasts on Reddit similarly claimed they managed to jailbreak the AI chatbot and bring out its ‘evil’ alter ego named ‘Dan’. In December, a tech enthusiast claimed he managed to ‘hack’ a Chevrolet dealer’s AI chatbot, and prompted it to agree to a deal to sell him the Chevy Tahoe for US$1 (AU$1.50).
NTU researchers said the experiment illustrated the security risks that lie with these mainstream AI chatbots, and how relatively easy it is to circumvent those restrictions.
“As LLMs continue to evolve and expand their capabilities, manual testing becomes both labour-intensive and potentially inadequate in covering all possible vulnerabilities. An automated approach to generating jailbreak prompts can ensure comprehensive coverage, evaluating a wide range of possible misuse scenarios,” noted Mr. Deng Gelei, PhD student at NTU.