




As AI-generated content floods the internet, AI models might end up ‘drowning out’ human-made material online, as well as the content that they’ve produced, according to a latest study by researchers at Toronto, Cambridge, Oxford, and Edinburgh universities, and Imperial College London.
The researchers teamed up for a study to find out what would happen if large language models (LLMs) “contribute [to] much of the language found online”.
AI models like ChatGPT and Stable Diffusion scrape for publicly available data online to produce its own ‘original’ content. But if this goes overboard, they found that it potentially brings about what they describe as a “model collapse.”
AI “Model Collapse”
Authors of the paper described “model collapse” as a “degenerative process whereby, over time, models forget the true underlying data distribution, even in the absence of a shift in distribution over time.”
In other words, it’s a phenomenon where AI models might forget the OG human-produced data that they’re originally trained with. This results in AI models “polluting the training set of the next generation of models”.
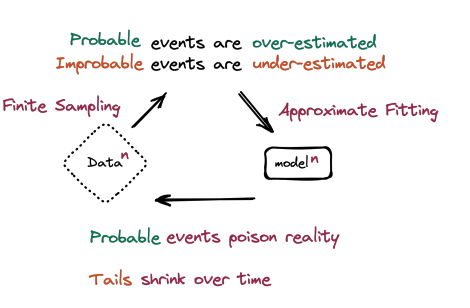
“… being trained on polluted data, they then mis-perceive reality,” noted the researchers. This means that we could expect more low-quality content from present and future AI models as a result of their continual ‘hallucinations.’
“We are witnessing exponential growth in synthetic data, which will soon surpass the volume of real data. Now, consider the implications when an AI model utilises synthetic data produced by other AI systems. This will magnify inherent challenges tied to data, including biases, data imbalances, and inconsistencies in representation,” Dr. Seyedli Mirjalili, Professor of AI at Torrens University, tells The Chainsaw.
“If not carefully managed, these amplified issues can lead to biases, misinterpretations, and potential misinformation,” he adds.
A snake eating its own tail
Researchers examined a scenario from an AI model called OPT-125m, where supposedly improved iterations of the model demonstrated a degradation in quality when it came to providing information about a query.

In the image above, we can see that the original human input was clear, accurate information about Revival Architecture in Europe in the 14th century. However, subsequent OPT-125m models generated information that contained awkward sentence structures, emoji-like symbols, and wrong punctuation. Big yikes.
University of Toronto researchers describe this pattern as an “AI ouroboros”, or the phenomenon of a snake eating its own tail. In a never-ending cycle of destruction and rebirth, AI models are devouring existing (and sometimes, low-quality) data, and producing new content.
“A good analogy for this is when you take a photocopy of a piece of paper, and then you photocopy the photocopy — you start seeing more and more artefacts,” says Professor Nicolas Papernot, Assistant Professor of Electrical and Computer Engineering at the University of Toronto.
“Eventually, if you repeat that process many, many times, you will lose most of what was contained in that original piece of paper,” he adds.
Future LLM models
This is not the first research that confirms the ouroboros-like scenario faced by AI models. In a paper published in July, researchers from Rice and Stanford universities fed AI-generated content to AI models and found that it created a “self-consuming” loop.
Rice and Stanford researchers coined the condition Model Autophagy Disorder (MAD). Literally, these AI models went MAD thanks to their own data.
Researchers studying “model collapse” warn that this issue should be taken seriously if we want to “sustain the benefits of training from scraping large-scale data from the web.”
One way to do so, according to the paper, might be to find a way to preserve the original data that’s used to feed AI models. However, given the overwhelming troves of data that exist on the internet, this seems like yet another gargantuan task for scientists to solve.
“As we rely on more synthetic data, it is imperative that we establish rigorous standards and checks to ensure its quality and reliability… however, the concern remains: does [it] encompass all genders, races, and other diversities?” Professor Mirjalili explains.